Self-Supervised Learning综述小结
Pre-train Fine-tune
Pre-train Fine-tune算是一种Transfer Learning。
首先,假设按照SimCLR中的设定,将一般的模型分为两部分,分别为Encoder和Projection Head。Encoder结构类似于AutoEncoder中的Encoder部分,输出是一个低维的张量,可以称为输入数据的表征。Projection Head可以认为是一个全连接层,将Encoder输出的张量映射为更低维的张量(或者称为嵌入向量)。

Pre-train就是预训练Encoder部分,得到一个有用的表征,通过Projection Head得到输出的嵌入向量,进行损失函数计算和模型更新。然后在不同的下游任务中,删掉Projection Head,重新训练。
预训练Encoder的过程就是Pre-train;删掉Projection Head,重新训练的过程就叫做Fine-tune
此处的重新训练可以分为两种:
- ConvNet as fixed feature extractor:即删掉Projection Head后,重新训练一个Projection Head。
- Fine-tuning the ConvNet:即对Encoder进行微调,同时重新训练一个Projection Head
对于Self-supervised Learning,要明确其严格意义上讲叫做无监督表示学习。和传统的无监督学习不同,SSL最终还是会用到有标记数据,只不过相对于监督训练,可以在极小的有标记数据下实现较高的正确率。
SSL一般将Pre-train和下游任务的fine-tune分开,不过也有很多文章尝试将二者结合起来。总而言之,四个词总结为:
Unsupervised Pre-train, Supervised Fine-tune.
Self-supervised Learning
Self-supervised Learning就是通过大量无标记数据,找寻数据之间的内在关系,建立一个能够提取泛化特征的Encoder,然后根据下游任务的需要,在下游任务的少量有标记数据集中进行Fine-tune。从生物的角度讲,可以理解为在无标记数据集中培育一个干细胞,然后在具体的下游任务中,利用少量资源,就可以将干细胞分化为红细胞、白细胞、上皮细胞;而不是每次都搞大量资源从头开始造不同结构的不同细胞。根据寻找这种内在关系的方式不同,可以将SSL分为两个大类(也有文章分为三个大类):
- 基于生成/预测的SSL
- 基于对比的SSL
基于生成/预测的SSL
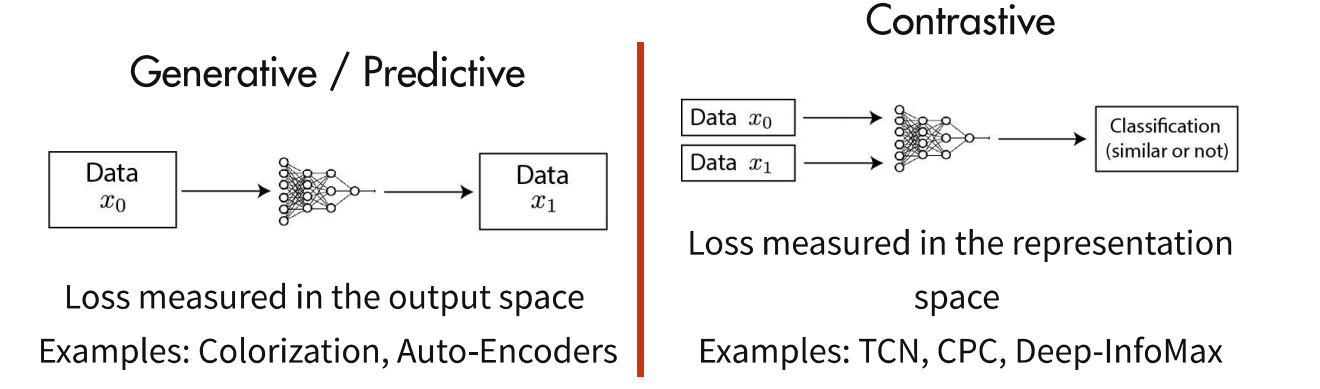
对于第一种,基于生成/预测的SSL,典型的有Context Encoders: Feature Learning by Inpainting,通过对图像的一部分扣除,将扣除后剩余部分进行Encoder,输出一个大小与扣除部分相同的张量,然后将扣除的部分和Encoder输出的部分做Loss,就可以让Encoder全面的知道输入的图片究竟是怎么样的。(当然也可以用来做一些图像补全工作)

基于对比的SSL
这部分是目前研究的重点,有一些典型的文章:
DIM
Learning Deep Representations By Mutual Information Estimation And Maximization
CPC
Representation Learning with Contrastive Predictive Coding
CMC
MoCo
Momentum Contrast for Unsupervised Visual Representation Learning
SimCLR(*****)
SimCLR及其改进版本SimCLR-v2,其完整过程请参考(大佬们已经总结得十分详细了,没有必要再整理了):
[精简思路](