MeanTeacher文章解读+算法流程+核心代码详解
MeanTeacher
本博客仅做算法流程疏导,具体细节请参见原文 ## 原文 原文链接点这里 ## Github 代码 Github代码点这里 ## 解读 论文解读点这里 ## 算法流程 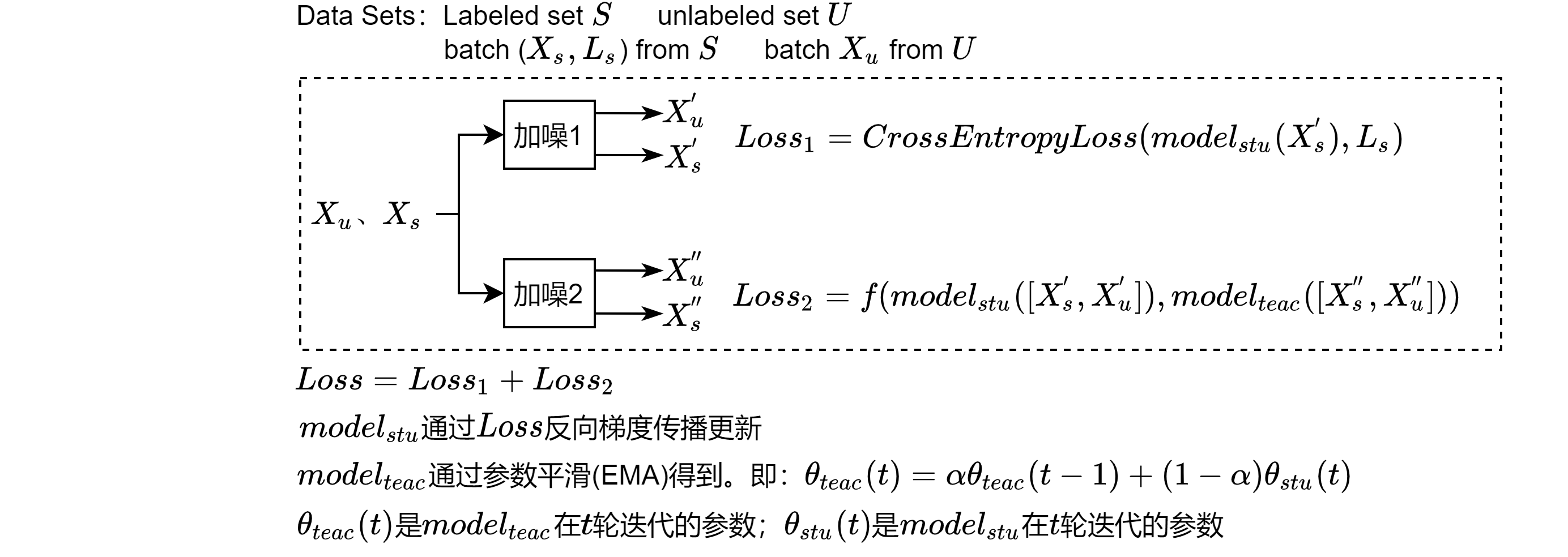 ## 代码详解
## 代码详解 1
2
3
4
5
6
7
8
9
10train_transform = data.TransformTwice(transforms.Compose([
data.RandomTranslateWithReflect(4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))]))
eval_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])1
for i, ((input, ema_input), target) in enumerate(train_loader):1
class_loss = class_criterion(model_out, target_var) / minibatch_size1
2consistency_weight = get_current_consistency_weight(epoch)
consistency_loss = consistency_weight * consistency_criterion(model_out, ema_logit) / minibatch_size1
2
3
4loss.backward() # student 模型的更新
optimizer.step()
global_step += 1
update_ema_variables(model, ema_model, args.ema_decay, global_step) # teacher 模型的更新
主要思想
算法比较简单,主要思想我觉得可以分为两部分:第一部分是原始样本的轻微扰动版本的预测结果应该与原样本属于同一类别;第二部分,希望通过模型的EMA版本作为分类更有可靠性的模型,即teacher来引导当前模型student模型训练,二者合并就是consistency_loss。