More is Better 信道建模扩增方法解读
简述
作者认为,在某一个时间点收集的数据集训练得到的网络在不同信道条件下的收集的数据集上表现不佳,是因为同一特征在不同信道条件下的表现不同(learning a channel-distorted fingerprint instead of the pure inherent fingerprint)。所以提出来一种数据增强方式可以模拟原始数据集中没有的信道和噪声变化,从而增强模型的鲁棒性。
文章提出了两种数据增强(扩充)的方式,分别针对于“发射端数据”和“接收端数据”进行扩充。在此,发射机数据可以理解为纯净的信号,接收机数据可以认为是已经通过信道的信号。
迁移学习和再训练的方法可以解决此类问题,但是作者认为These solutions are not always possible, as training during deployment is resource and time consuming.
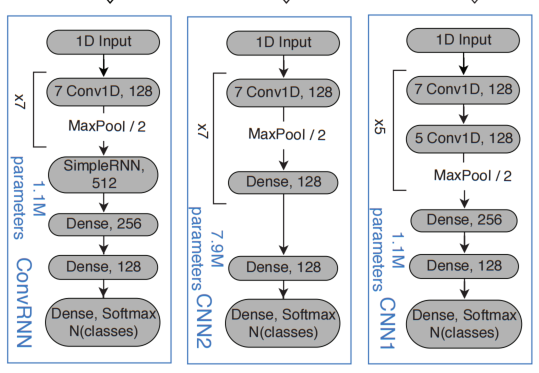
模型
三个不同的CNN。
数据集
Custom Dataset(Matlab仿真得到)
matlab wlan tool-box生成,IEEE 802.11a wifi协议。QPSK调制,码率为0.5。命名为Txdata(发射机数据)
对上述数据通过信道。得到Day1和Day2数据(信道不同)。
共三组,分别为Txdata、Day1、Day2.
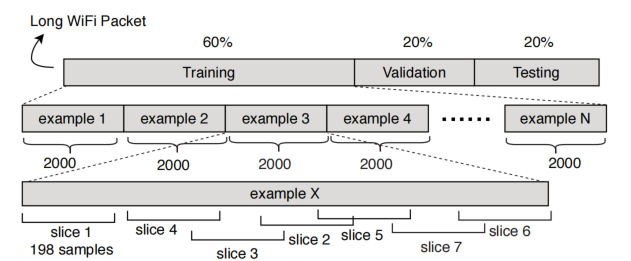
每组有16个dB,每个dB下有10个设备,每个设备的信号长19.6 million 采样点。19.6 million采样点中,前60%为训练集,20%为测试集,20%为验证集。
训练集、测试集、验证集中,每2000个采样点划分为一个example,形成独立传输。每个example中进行滑动窗分割,以保证模型所学特征的 shift invariance。
训练阶段取batchsize=128,size=[128, 198, 2]=[batchsize, length, channel]
DARPA Dataset(DARPA的时采数据)
it contains signals from 50, 250, 500, and 5000 WiFi devices transmitting IEEE 802.11a/g protocol.
此数据集中,example已经形成了,只需要进行slice分割即可。
分类正确率的衡量
slice的精度
正确预测的切片数除以总切片数来计算每个切片的精度。
example的精度
对每个example进行分类,将该example中所有slice的概率向量求和,并选择值最高的类作为预测类(其实就是投票)。我们通过将正确预测的example的数目除以测试example的总数来计算每个example的准确度。
数据增强
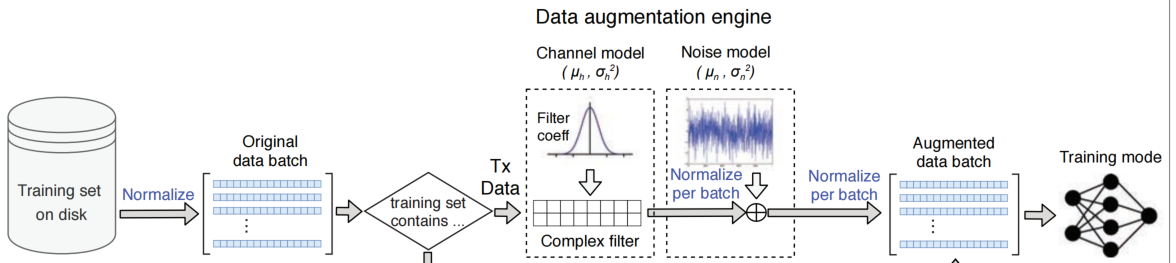
对于发射端数据的增强
分为channel模型和noise模型。顺序通过channel模型和一个noise模型。channel模型是一个fir滤波器(从特定的分布中抽取滤波点数,并与信号进行卷积)。noise模型是一个高斯噪声发生器。
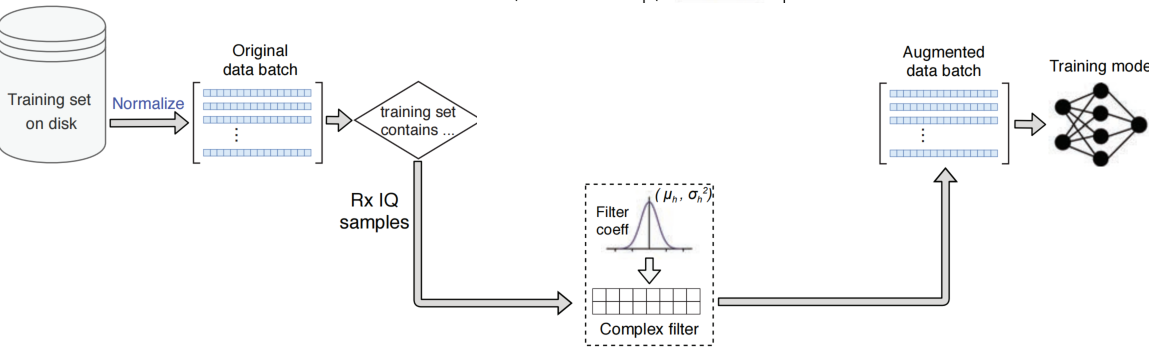
对于接收端数据的增强
实验结果
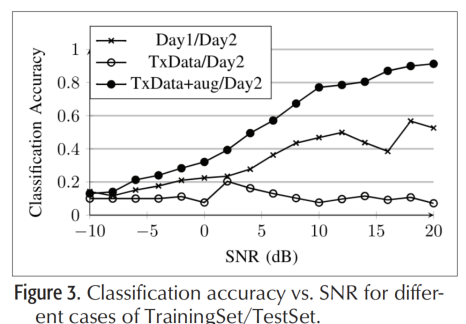
Day1训练Day2测试的结果可以看到,即使SNR=20dB,也仅有52%左右的正确率。但SNR=20dB时,Day1训练Day1测试可以达到99%左右。
同样的,用TxData训练,Day2测试,基本等于随机猜
再上述两个背景下,此文提出的方法,TxData+Aug(即模拟了各种信道的数据)训练,在Day2上测试的结果非常好。说明文章算法的有效性。
注意
文章中认为无线信道的衰减、反射和延迟,造成的结果是对iq星座图进行向上、向下扩展和旋转。