End-2-End model-free Transceiver design
Date: 2024.05.09 22:23 Author: Joffrey LC
Model-Free Training of End-to-End Communication Systems. Fayçal Ait Aoudia et.al. IEEE Journal on Selected Areas in Communications, November 2019 (pdf) (Citations 131)
Quick Overview
- 核心问题:end-to-end model (e.g., Autoencoder)需要可微信道模型。
- Training the receiver using the True gradient, while training the transmitter using an approximation of the gradient.
For example, some parts of the transceiver, such as quantization, which is non-differentiable.
- 与常规反向梯度传播的算法作比较,AWGN信道和瑞利快衰落信道上,实现了相同的性能。
Gradient estimation without channel model
The gradient of Receiver
The True gradient between difference of the output of model and the training sample.
The gradient of Transmitter

对于原Loss函数:
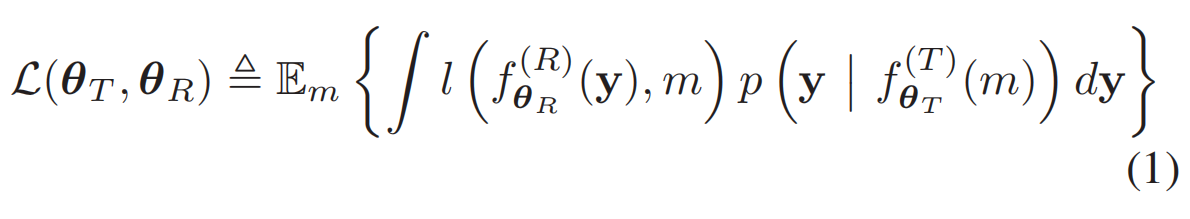
进行变换得到:
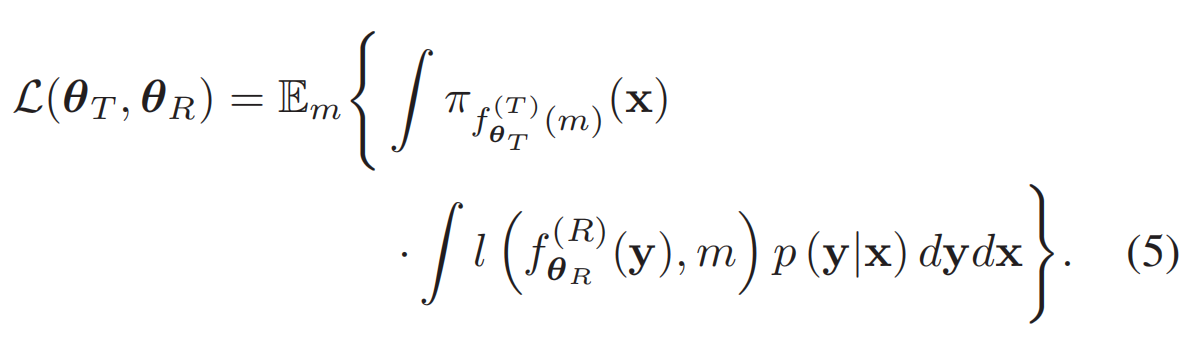
然后求导得到:
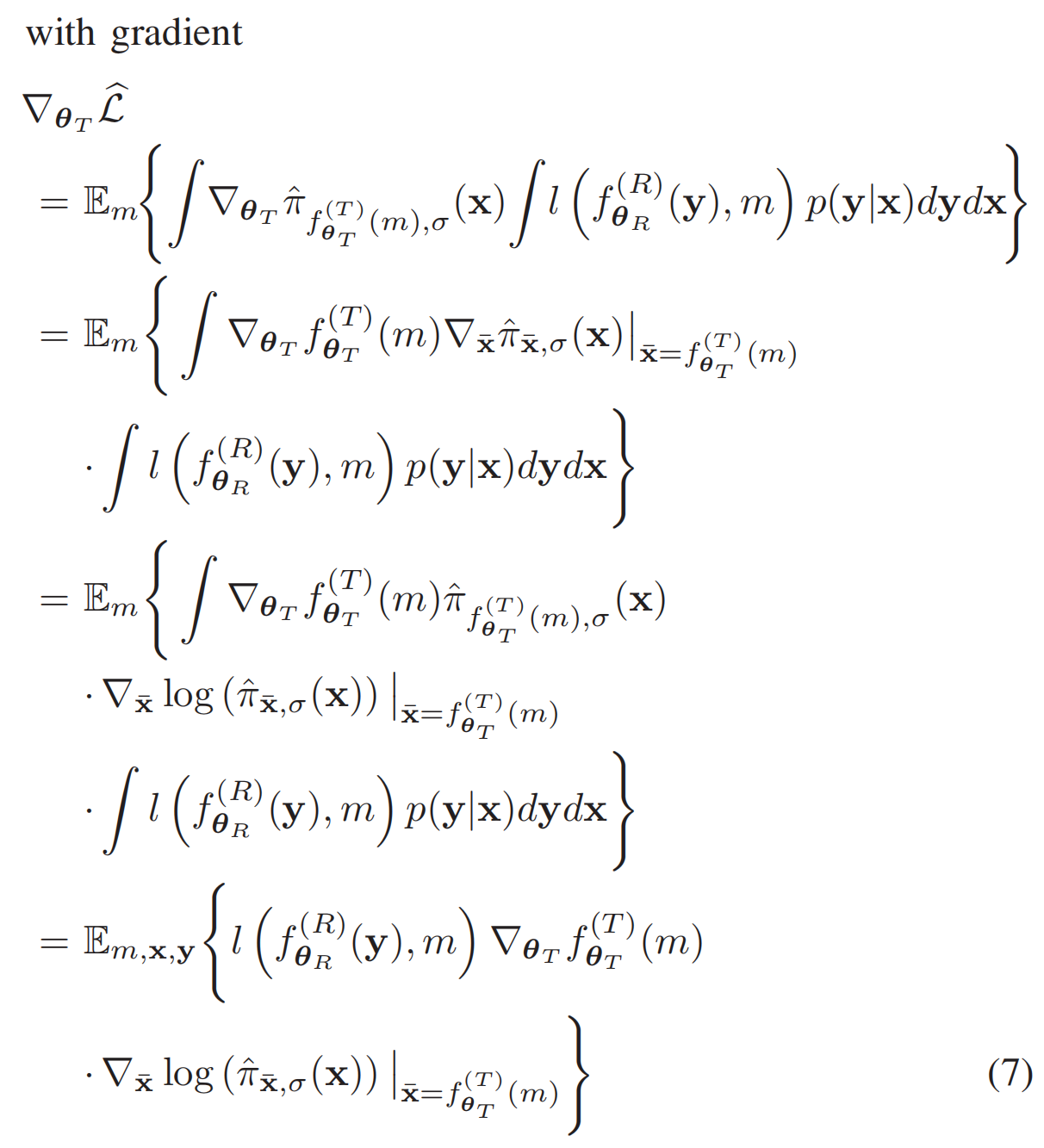

Training end-to-end communication systems
Transmitter: All non-differentiable operations on the transmitter output, e.g., quantization, can be assumed to be part of the channel (non-differentiable channel)
Receiver: the last layer of the receiver model is a softmax layer.
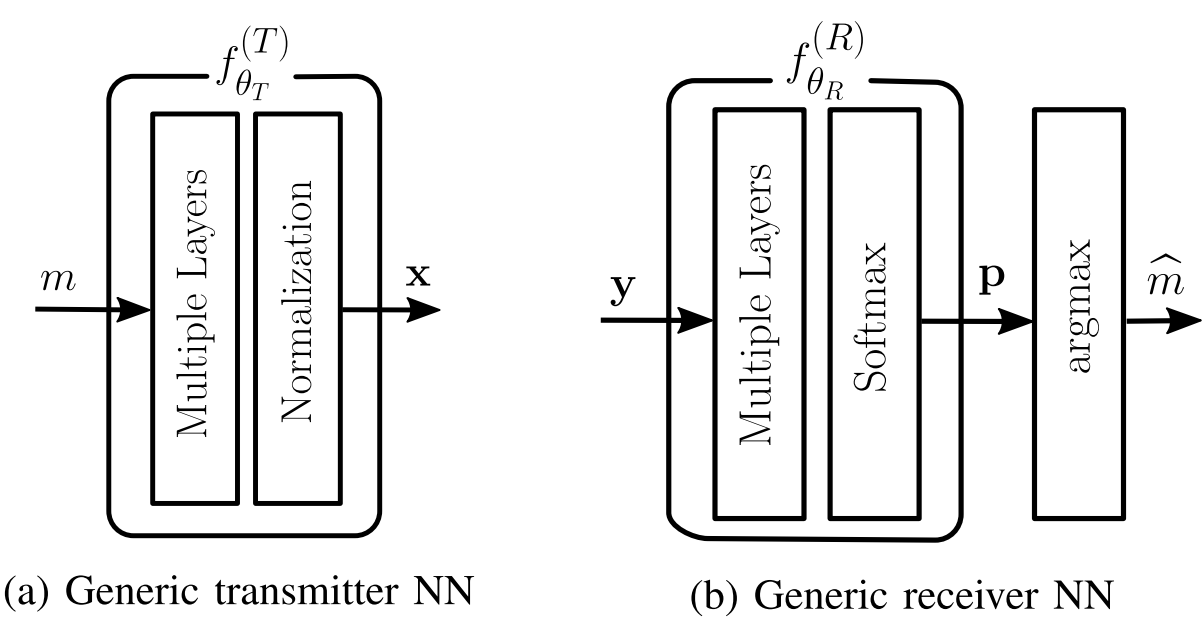
Alternating Training for Receiver and Transmitter, and one is training, the another are kept fixed.
Training the Receiver

Note that there is no relaxation of the Transmitter output, since it is not required to approximate the receiver gradient.
Training the Transmitter

Not that we need to transmit the per-example losses to the transmitter end over a reliable feedback link, and then update the Transmitter model.
Evaluation
Relaxation is achieved by adding a zero-mean Gaussian vector.
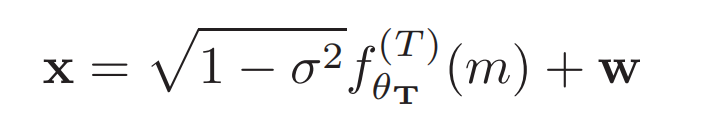
\(\sqrt{1-\sigma^2}\)是为了功率归一化(信号和噪声功率和为1)
看起来会选择较小的\(\sigma^2\),从而使得approximation逼近真实的gradient,但是作者实验结果证明过小的\(\sigma\)会使得估计器方差变大并且导致收敛变慢。